Original Link: https://www.anandtech.com/show/2412
PCI Express 2.0: Scalable Interconnect Technology, TNG
by Kris Boughton on January 5, 2008 2:00 AM EST- Posted in
- CPUs
It should come as no surprise to anyone that the gaming industry is quite capable of forcefully driving the need for innovation - often found in the form of faster processors, more powerful 3D graphics adapters, and improvements in data exchange protocols. One such specification, PCI Express (PCI-E), was prompted for development when system engineers and integrators acknowledged that the interconnect demands of emerging video, communications, and computing platforms far exceeded the capabilities of traditional parallel buses, such as PCI. Although PCI Express is really nothing more than a general purpose, scalable I/O signaling interconnect, it has quickly become the platform of choice for industry segments that desperately need the high-performance, low latency, scalable bandwidth that it consistently provides. Graphics card makers have been using PCI Express technology for more than a generation now and today's choice of PCI Express-enabled devices is becoming larger by the minute.
Unlike older parallel bus technologies such as PCI, PCI Express adopts a point-to-point serial interface. This architecture provides dedicated host to client bandwidth, meaning each installed device no longer must contend for shared bus resources. This also removes a lot of the signal integrity issues such as reflections and excessive signal jitter associated with longer, multi-drop buses. Cleaner signals mean tighter timing tolerances, reduced latencies, and faster, more efficient data transfers. To the gamer, of course, only one thing really matters: more frames per second and better image quality. While PCI-E doesn't directly provide for that relative to AGP, it has enabled some improvements along with the return of multi-card graphics solutions like SLI and CrossFire. For these reasons, it is no wonder that PCI Express is the interconnect of choice on modern motherboards.
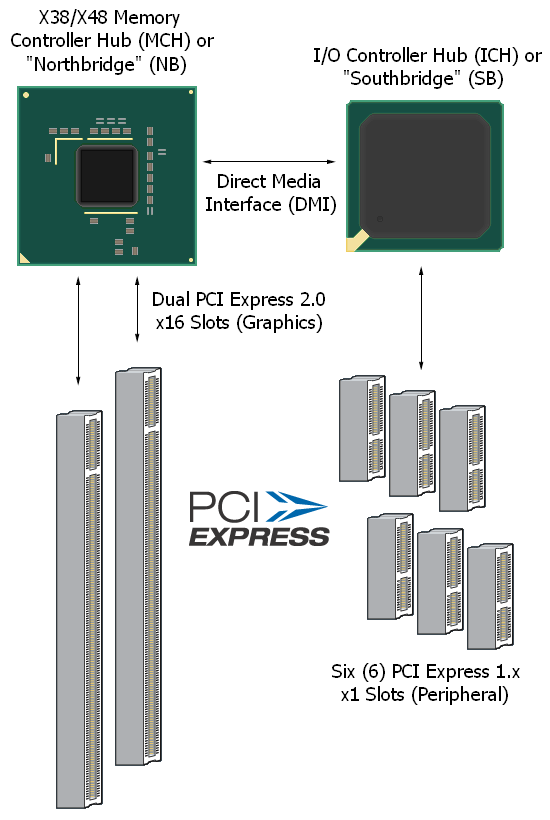
The typical Intel chipset solution provides a host of PCI Express resources. Connections to the Memory Controller Hub (MCH) are usually reserved for devices that need direct, unfettered, low-latency access to the main system memory while those that are much less sensitive to data transfer latency effects connect to the I/O Controller Hub (ICH). This approach ensures that the correct priority is given to those components that need it the most (usually graphics controllers). When it comes to Intel chipsets, a large portion of the market segment distinction comes from the type and quantity of these available connections. Later we will look at some of these differences and discuss some of the performance implications associated with each.
In late 2006, PCI-SIG (Special Interest Group) released the 2.0 update to the PCI Express Base Specification to members for review and comment. Along with the introduction of a host of new features comes the most predominant change of all, an increase in the signaling rate to 5.0GT/s (double that of the PCI Express 1.x specification of 2.5GT/s). This increase effectively doubles the maximum theoretical bandwidth of PCI Express and creates the additional data throughput capabilities that tomorrow's demanding systems will need for peak performance.
Both ATI/AMD and NVIDIA have released their first generation of PCI Express 2.0 capable video cards. ATI has the complete Radeon HD 3000 series while NVIDIA offers the new 8800 GT as well as a 512MB version of the 8800 GTS (G92) built using 65nm node technology. Last month we took an in-depth look at these new NVIDIA cards - our testing, comments, and conclusion can be found here. We reviewed the ATI models a little earlier in November - the results are interesting indeed, especially when compared to NVIDIA's newest offerings. Take a moment to review these cards if you have not already and then come read about PCI Express 2.0, what it offers, what has changed, and what it means to you.
PCI Express Link Speeds and Bandwidth Capabilities
PCI Express uses a highly scalable architecture that is capable of delivering high bandwidth with a relatively low pin-count, dramatically simplifying design complexity while simultaneously allowing for smaller interface footprints. This is accomplished through the use of Low Voltage Differential Signal (LVDS) signal pairs - a simple two wire connection allowing for 1 bit to be transferred per clock (therefore 1GT/s is equal to 1Gbps). A pair per direction makes bi-directional signaling possible, which effectively doubles the throughput to 2 bits per cycle. Together these four pins comprise a single "lane." No additional pins are needed for data transfer as the clock signal is transmitted using these same pins through the use of an encoding scheme known as 8b/10b encoding. Without getting into too much detail this means that 8 bits of data are transferred using a 10-bit signal. While this does add 25% overhead to each data transfer, it eliminates the need to route separate traces for clock signals, the downside being that the maximum throughput is reduced by about 20%. Because the clock rate is so high (2.5GHz), the PCI Express protocol is able to transfer up to 500MB/s of bi-directional data with just four pins (compared to the legacy PCI bus which transfers 133MB/s of data using 32 pins). Higher data transfer rates require either the use of numerous parallel traces or increased clocking rates - in this case we can see that the tradeoff has been clearly been made in favor of a low-pin count.
Multiple lanes can be grouped through a method knows as training, wherein the downstream device and the host negotiate how many lanes will be assigned. Although plugging a PCI Express card into a slot smaller than itself is not physically possible, plugging into a larger slot is mechanically possible. During training, the host device simply queries the device for its maximum link speed and assigns resources as needed. (Keep in mind that link speed is a bit of a misnomer - the PCI Express physical link layer always operates at the same frequency; it's the number of assigned lanes that changes). This method becomes a little more complicated in the case where the mechanical size of the slot does not necessarily match the host's maximum offered link speed. For example, many of today's X38-based motherboards include a third x16 slot but are only capable of providing x4 bandwidth (PCI Express 1.x) - more on why this is later. In this case, the installed device must be willing to operate at a reduced link speed. The PCI Express interface supports interconnect widths of x1, x2, x4, x8, x16, and x32. As an aside, PCI-E x32 slots are rarely seen because of their exceptional length, but thanks to PCI Express 2.0 we can now get the same bandwidth in PCI-E x16 form factor.
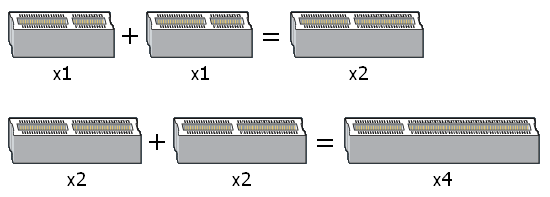
The part of the installed card's edge connector to the left of the key notch is always the same, no matter the card. Power, ground, reference voltages, and pads for control, training, and link maintenance are located here and are the required minimum required for operation. Data transfers to and from the device are accomplished using repeating blocks of pads - those that form the signals that comprise a single lane. The longer the slot is from the right of the keyway the higher the speed it offers (this assumes that it does in fact offer a maximum link speed congruent with its mechanical size). This all makes determining a device's default link speed quite easy - a quick look at the length of the edge connector and you have everything you need to know.
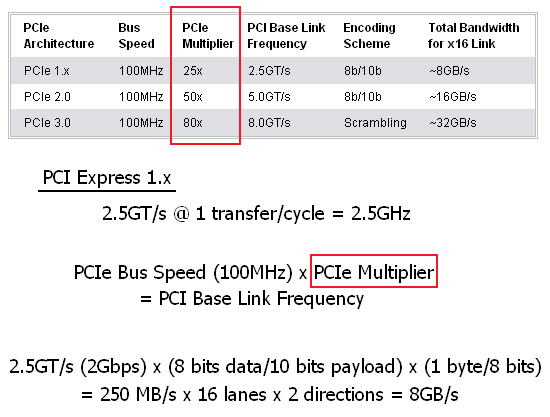
The table below compares PCI Express 1.x with 2.0 as well as 3.0 (which is now in the development stage - expect to see products based on this revision sometime in 2010). PCI Express 2.0 builds upon PCI Express 1.x primarily through the doubling of the clock rate to 5.0GHz (up from 2.5GHz). This brings to light an important point: earlier we noted that the PCI Express physical link layer always operates at the same speed. This is true except in the case where a PCI Express 1.x device is installed in a PCI Express 2.0 compliant slot - although the host is capable of the higher signaling frequency the device is not; the result being the use of the slower (2.5GT/s) clock rate. Note how the 8b/10b encoding overhead is factored into the actual usable bandwidth calculation.

Using PCI Express 2.0, motherboard designers can now either offer double the bandwidth in an equivalent size slot or can choose to create smaller layouts without sacrificing performance. In any case, this additional design flexibility paves the way for significant improvements in future products. PCI Express 3.0 will likely double the bandwidth provided by the previous generation again. You may have noticed though that the change must come from something more than just a decrease in the cycle time. This will be due a change in the encoding scheme - PCI-E 3.0 will stop using 8b/10b encoding, and whether or not the new scheme is truly more efficient than that used today remains to be seen. Expect the same level of backward-compatibility though as PCI-SIG is already assuring us that our then ancient PCI Express 1.x cards will run without difficulty in a PCI Express 3.0 slot. Let's take a closer look at exactly why they can make such a bold claim.
PCI Express Backwards Compatibility
PCI Express is a layered protocol composed of a three distinct partitions: physical (PHY), data link layer (DLL), and transaction layer (TL). This modular approach is what allowed the fundamental change in the physical layer data rate from 2.5GT/s to 5.0GT/s to go unnoticed by the upper layers. The PCI-E bus speed remains unchanged at 100MHz; the only feature that changed is the rate at which data is transferred across the board. This suggests that there is significant signal manipulation required on both the transmit and receive ends of the pipe before data is available for use. In the end, the change is akin to selecting a higher multiplier for a CPU: although the processor operates at an increased frequency, it continues to communicate with the interface component at the same rate. This concept will help us to introduce the concept of a "PCI-E Multiplier." This number is static and cannot be changed (except by the motherboard, which occurs during the training process). PCI Express 3.0 should further increase the PCI-E Multiplier to 80x, which will bring the base link frequency very near the maximum theoretical switching rate for copper (~10Gbps).
As we mentioned before, installing a PCI Express 1.x card in a PCI Express 2.0 compliant slot will result in PCI Express 1.x speeds. The same goes for installing a PCI Express 2.0 card in a PCI Express 1.x compliant slot. In every case, the system will operate at the lowest common speed with the understanding that all PCI-E 2.0 devices must be engineered with the ability to run at legacy PCI-E 1.x speeds.
Unfortunately, there have been some reports of new PCI-E 2.0 graphics cards refusing to POST (Power On Self-Test) in motherboards containing chipsets without PCI Express 2.0 support. We can assure you this is not by design as the PCI-SIG PCI Express 2.0 Specification is very clear on the issue - PCI Express 2.0 is backward-compatible with PCI Express 1.x in every case. With this in mind, and knowing that some PCI Express 1.x motherboards have no problems running the new graphics cards while others do, we have no choice but to blame the board in the case of no video. Unfortunately, this makes it difficult to determine if problems await during the upgrade process; you must first consult with others that use the same video card/motherboard combination. Thankfully the cases of incompatibility seem to be few and far between.
Intel Chipset PCI Express Resource Assignments
Intel desktop platforms make use of a pair of bus controllers, commonly referred to as the chipset. The Memory Controller Hub (MCH) or "Northbridge" (NB) is responsible for directly interfacing the processor with memory as well as all other system resources, and it communicates all information to the CPU over the Front Side Bus (FSB). The memory controller, which makes up a portion of the MCH, is responsible for arbitrating requests for bus time and translating requests for data located in system memory into the appropriate commands and addresses needed to retrieve and deliver that information to the CPU and other DMA (Direct Memory Access) devices. This discussion, although relevant to understanding the operation of the MCH, is better left for another day. Instead, we would like to concentrate on the second major function of the Northbridge, which is providing PCI Express ports for lane assignments and data transfers. Incorporating the PCI Express controller into the Northbridge ensures that installed graphics cards have easy access to system memory and CPU resources.
The Northbridge communicates with the I/O Controller Hub (ICH), or "Southbridge", using an interface that Intel calls Direct Media Interface (DMI) at a maximum transfer rate of 2GB/s. This connection is actually nothing more than a PCI Express x4 link with a dedicated transaction layer which handles routing of all input/output (I/O) data from attached peripherals such as hard disks, optical drives, Ethernet controllers, onboard audio, and Universal Serial Bus (USB) and PCI devices. The Intel 875/ICH5 chipset, the last to make use of then-aging AGP technology, made use of a PCI link in this location which provided only 266MB/s (133MB/s in each direction) total bandwidth. The 915/ICH6 "Express" chipset was the first to make use of this higher speed link - a change that improved the performance of technologies such as SATA (both 1.5Gbps and 3.0Gbps) and onboard 1Gbps Ethernet ports, giving them the headroom they need to function at their maximum potential.
Each PCI Express "Port" in the Northbridge is actually a pre-configured x4 lane (meaning that lane resources can only be assigned in chunks of four). The table below shows the PCI Express resources available from some of the more recent Intel chipsets. Reviewing this we see that the only real difference between the older 965P and 975X chipset, in term of graphics capabilities, was the ability for the 975X chipset to split the available x16 lane into two x8 lanes for CrossFire configurations. This difference was more than likely for market distinction and not a true limitation of the chipset. PCI Express is highly scalable and there is no obvious reason as to why 2x8 CrossFire on a P965 chipset should not work. Much like P965, P35 is limited to single x16 configurations.
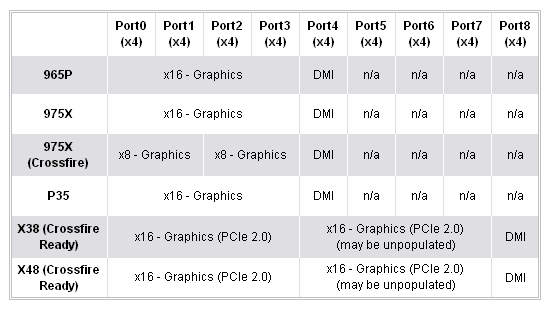
The real change comes with the introduction of Intel's current X38 flagship chipset. The X38 chipset provides two true PCI Express 2.0 capable x16 lanes for use with the latest PCI-E 2.0 graphics cards. A pair of ATI/AMD graphics cards in CrossFire will receive a full 16 lanes of bandwidth each regardless of the PCI Express specification they use - the only difference is the maximum theoretical throughput (16GB/s with PCI-E 2.0 and 8GB/s with PCI-E 1.x). Future X48 chipsets, which appear to be speed-binned X38 chipsets, will provide exactly the same capabilities.
Some 975X users may have asked themselves if it was possible to "unlock" x16 link speeds for their two graphics cards running in CrossFire - if one card can run at x16 speed, why not two? (The slots are certainly big enough to house the cards and all the right traces are on the motherboard.) As we can see, the chipset is physically incapable of that configuration as the PCI Express resources needed to form two x16 links simply are not there - there is nothing to change and nothing to re-configure.
In the case of each "Express" chipset, a final x4 port is available for the purposes of linking the Southbridge to the Northbridge. Although the X38/X48 chipsets are true PCI Express 2.0 parts, they configure Port8 for PCI Express 1.x speeds, as the ICH9(R) Southbridge is only a PCI Express 1.x enabled part. As such, we expect that Intel's upcoming ICH10(R) will make full use of PCI-E 2.0 as well meaning that the associated DMI connection should see a nice boost in speed to 4GB/s (double that of today). Below is a simple physical representation of the X38/X48 PCI Express resources.
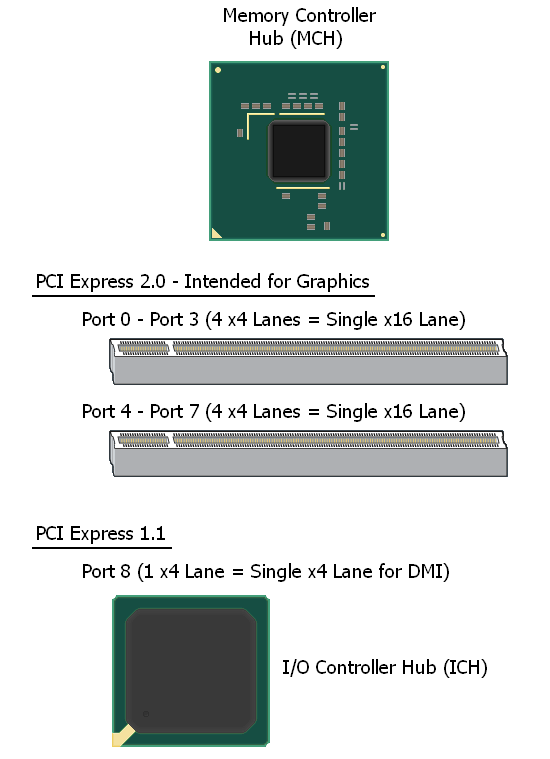
PCI Express 2.0 to 1.x backwards-compatibility allowed Intel the opportunity to release a PCI Express 2.0 MCH now with an ICH to follow, something that would not have been possible otherwise. Traditionally we see a new ICH at the same time as the MCH. Given the extra time Intel has for the refinement of ICH10(R), we will be satisfied with nothing less than perfection.
The ICH provides the system with an additional six PCI Express 1.x lanes (to be grouped as desired by the motherboard design company). However, as we have seen, the DMI link is capable of sustaining a maximum throughput of x4 speed to the Northbridge. This means that in the case of fully populated link states a lot of the bandwidth originating from downstream-attached peripherals is bottlenecked if outputting anything more than short bursts of data. Coincidentally, this is why pseudo-CrossFire configurations on P965 and P35 chipsets are limited to x4 speeds for the second card (additionally, x6 link states are not allowed). For the same reasons, the use of a third graphics card in X38/X48 configurations for physics acceleration purposes sees the same limitation. Previous testing indicates that there may be a slight performance penalty associated with x16/x4 CrossFire compared to x8/x8 or x16/x16 solutions, but despite having less than one fourth the bandwidth we do not see a massive loss of performance. In other words, we are definitely not at the point yet where we are using all of the available bandwidth for even PCI-E 1.x x16 slots.
Final Thoughts
As we have seen, PCI Express 2.0 is the next step in the quest for more bandwidth. This trend has been around since the beginning of time as each successive generation usually doubles the maximum bandwidth of the previous generation (or technology). This only makes sense as according to Moore's Law the number of transistors placed in an inexpensive integrated circuit approximately doubles every two years - improvements in interconnect technology necessary to support these advancement are the logical extension of this law. Looking for performance improvements in today's technology offerings with the next-generation interconnect technology (like PCI Express 2.0) is largely futile. The real benefit may come in the next round of video card releases - or perhaps Generation Next^2. Still, those that are quick to brush off PCI Express 2.0 as ineffective and unimportant should recall the past. The difference in performance experienced during the transition from AGP to PCI Express 1.x was not necessarily a revolution at the time, but there are benefits to using PCI-E instead of the aging PCI interface, and we may see new implementations of PCI-E technology that make the 2.0 revision more important.
Just about every interconnect technology is moving from high-pin count parallel interfaces to high-speed, low-pin count, serial, point-to-point interfaces. We have seen the incredible difference moving to a low-latency, high-bandwidth interfaces made in the transition from PATA to SATA as well as PCI/AGP to PCI Express (AGP was really just a kludged-together remake of PCI technology). Moreover, we will see it again in the near future when Intel leaves behind their antiquated FSB topology for QuickPath - something AMD did years ago with the release of their Opteron/Athlon 64 line featuring HyperTransport Technology. Removing the MCH altogether means moving the memory controller on die as well as relocating PCI Express resources to the CPU. The X38/X48 chipset will simultaneously be the first and last Intel MCH to make use of PCI Express 2.0 technology. (Unless the fabled P45 chipset, the 65nm die-shrink of P35 with additional improvements, see's the light of day.)
No doubt, those that run their systems with PCI Express 2.0 graphics cards installed will see an increase in MCH power consumption. Although we can't tell you exactly what share of the consumption figure is due to PCI Express circuit operation, what we can tell you is that it went up - those portions of the die that must run at the base link frequency of 5.0GHz have at least doubled from the days of PCI Express 1.x. What this means to the bottom line we don't know - perhaps this can help us explain why X38 seems to be so darn hot at times.
Maybe in the future we will see a mechanism that allows us to force PCI Express 1.x operation with PCI Express 2.0 capable graphics cards on some motherboards. (We do not recall testing many boards that had this option - allowing for PCI Express 1.1 or 1.0a.) This would be the only way for us to determine if the increased signaling rate makes a big a difference for today's products, but while we would hope it helps we remain skeptical at best. Purchasing a PCI Express 2.0 graphics cards at this time is future proofing more than anything else; we haven't noticed any performance differences when comparing PCI-E 1.x chipsets to PCI-E 2.0 chipsets with the newer GPUs, and we don't expect you to either. PCI-E 2.0 may prove more useful as a way to provide four x8 slots that each offer the same bandwidth as the older 1.x x16 slots. With Triple-SLI, Tri-Fire, and talk of GPU physics accelerators, including additional high-bandwidth slots on motherboards makes sense.






