Intel Xeon 7460: Six Cores to Bulldoze Opteron
by Johan De Gelas on September 23, 2008 12:00 AM EST- Posted in
- IT Computing
Our First Virtualization Benchmark: OLTP Linux on ESX 3.5 Update 2
We are excited to show you our first virtualization test performed on ESX 3.5 Update 2. This benchmarking scenario was conceived as a "not too complex" way to test hypervisor efficiency; a more complex real world test will follow later. The reason we want to make the hypervisor work hard is that this allows us to understand how much current server CPUs help the hypervisor, keeping the performance overhead of virtualization to a minimum. We chose to set up a somewhat unrealistic (at this point in time) but very hypervisor intensive scenario.
We set up between two and six virtual machines running an OLTP SysBench 0.4.8 test on MySQL 5.1.23 (INNODB Engine). Each VM runs as a guest OS on a 64-bit version of Novell's SLES 10 SP2 (SUSE Linux Enterprise Server). The advantage of using a 64-bit operating system on top of ESX 3.5 (Update 2) is that the ESX hypervisor will automatically use hardware virtualization instead of binary translation. Each virtual machine gets its own four virtual CPUs and 2GB of RAM.
To avoid I/O dominating the entire benchmark effort, each server is connected to our Promise J300S DAS via a 12Gbit/s Infiniband connection. The VMs are installed on the server disks but the databases are placed on the Promise J300S, which consists of a RAID 0 set of six 15000RPM Seagate SAS 300GB disks (one of the fastest hard disks you can get). A separate disk inside the Promise chassis is dedicated to the transactional logs; this reduces the disk "wait states" from 8% to less than 1%. Each VM gets its own private LUN.
Each server is equipped with an Adaptec RAID 5085 card. The advantage is that this card is equipped with a dual-core Intel IOP 348 1.2GHz and 512MB of DDR2, which helps us ensure the RAID controller won't be a bottleneck either.
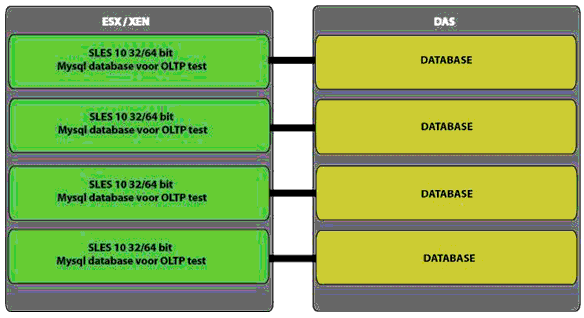
Our first virtualized benchmark scenario; the green part is the server and the yellow part is our Promise DAS enclosure.
We use Logical Volume Management (LVM). LVM makes sure that the LUNs are aligned and start at a 64KB boundary. The file system on each LUN is ext3, with the -E stride=16 option. This stride is necessary as our RAID strip size is 64KB and Linux (standard) only allows a block size of 4KB.
The MySQL version is 5.1.23 and the MySQL database is configured as follows:
max_connections=900
table_cache=1520
tmp_table_size=59M
thread_cache_size=38
#*** INNODB Specific options ***
innodb_flush_log_at_trx_commit=1
innodb_log_buffer_size=10M
innodb_buffer_pool_size=950M
innodb_log_file_size=190M
innodb_thread_concurrency=10
innodb_additional_mem_pool_size=20M
Notice that we set flush_log_at_trx_commit = 1, thanks to the Battery Backup Unit on our RAID controller; our database offers full ACID behavior as appropriate for an OLTP database. We could have made the buffer pool size larger, but we also want to be able to use this benchmark scenario in VMs with less than 2GB memory. Our 1 million record database is about 258MB and indices and rows fit entirely in memory. The reason we use this approach is that we are trying to perform a CPU benchmark; also, many databases now run from memory since it is pretty cheap and abundant in current servers. Even 64GB configurations are no longer an exception.
Since we test with four CPUs per VM, an old MySQL problem reared its ugly head again. We found out that CPU usage was rather low (60-70%). The reason is a combination of the futex problems we discovered in the old versions of MySQL and the I/O scheduling of the small but very frequent log writes, which are written immediately to disk. After several weeks of testing, we discovered that using the "deadline" scheduler instead of the default CFQ (Complete Fair Queuing) I/O scheduler solved most of our CPU usage problems.
Each 64-bit SLES installation is a minimal installation without GUI (and runlevel = 3), but with gcc installed. We update the kernel to version 2.6.16.60-0.23. SysBench is compiled from source, version 0.4.8. Our local Linux gurus Philip Dubois and Tijl Deneut have scripted the benchmarking of SysBench. A master script on a Linux workstation ensures SysBench runs locally (to avoid the time drift of the virtualized servers) and makes SQL connections to each specified server while running all tests simultaneously. Each SysBench database contains 1 million records, and we start 8 to 32 threads, in steps of 8. Each test performs 50K transactions.








34 Comments
View All Comments
npp - Tuesday, September 23, 2008 - link
I didn't got this one very clear - why should a bigger cache reduce cache syncing traffic? With a bigger cache, you would have the potential risc of one CPU invalidating a larger portion of the data another CPU has already in its own cache, hence there would be more data to move between the sockets at the end. If we exaggerate this, every CPU having a copy of the whole main memory in its own cache would obviously lead to enormous syncing effort, not the oposite.I'm not familiar with the cache coherence protocol used by Intel on that platform, but even in the positive scenario of a CPU having data for read-only access in its own cache, a request from another CPU for the same data (the chance for this being bigger given the large cache size) may again lead to increased inter-socket communication, since these data won't be fetched from main memory again.
In all cases, inter-socket communication should be much cheaper than the cost of a main memory access, and it shifts the balance in the right direction - avoiding main memory as long as possible. And now it's clear why Dunnington is a six- rather than eight-core - more cores and less cache would yield a shift in the entirely opposite direction, which isn't what Intel is needing until QPI arrives.
narlzac85 - Wednesday, September 24, 2008 - link
In the best case scenario (I hope the system is smart enough to do it this way), with each VM having 4 CPU cores, they can keep all their threads on one physical die. This means that all 4 cores are working on the same VM/data and should need minimal access to data that another die has changed (if the hypervisor/hostOS processes jump around from core to core would be about it). The inter-socket cache coherency traffic will go down (in the older quad cores, since the 2 physical dual cores have to communicate over the FSB, it might as well have been the same as an 8 socket system populated by dual cores)Nyceis - Tuesday, September 23, 2008 - link
Can we post here now? :)JohanAnandtech - Wednesday, September 24, 2008 - link
Indeed. As the IT forums gave quite a few times trouble and we assume quite a few people do not comment in the IT forums as they have to register again. I am still searching for a good solution as these "comment boxes" get messy really quickly.Nyceis - Tuesday, September 23, 2008 - link
PS - Awesome article - makes me want hex-cores rather than quads in my Xen Servers :)Nyceis - Tuesday, September 23, 2008 - link
Looks like it :)erikejw - Tuesday, September 23, 2008 - link
Great article as always.However the performance / watt comparison is quite useless for virtualization systems though since they scale well at a multisystem level and for other reasons too
I won't hurt to make them but what users really care of is performance / dollar (for a lifetime)
Say the system will be in use for 3 years.
That makes the total powerbill for a 600W system about 2000$, less then the cost of one Dunnington and since the price difference between the Opteron and Dunnington cpus is like 4800$ you gotta be pretty ignorant to choose system with the performance / watt cost.
Lets say the AMD system costs 10000$ and the Intel 14800$(will be more due to Dimm differences) and have a 3 year life then the total cost for the systems and power will be 12000 and 16800.
That leaves us with a real basecost/transaction ratio of
Intel 5.09 : 4.25 AMD
AMD is hence 20% more cost effective than Intel in this case.
Any knowledgable buyer has to look at the whole picture and not at just one cost factor.
I hope that you include this in your other virtualization articles.
JohanAnandtech - Wednesday, September 24, 2008 - link
You are right, the best way to do this is work with TCO. We have done that in our Sun fir x4450 article. And the feedback I got was to calculate on 5 years, because that was more realistic.But for the rest I fully agree with you. Will do asap. How did you calculate the power bill?
erikejw - Wednesday, September 24, 2008 - link
Sounds good, will be interesting.The calculations was just a quick and dirty 600W 24/7 for 3 years and using current power prices.
VM servers are supposed to run like that.
It would also be interesting to see how the Dunnington responds when using more virtual cores than physical. Will the decline be less than the older Xeons?
What is a typical (core)load when it comes to this?
The Nehalems will respond more like the Athlons in this regard and not loose as much when the load increases, at a higher level than AMD though.
I realised the other day that it seems as AMD have built a servercpu that they take the best of and brings to the desktop market and Intel have done it the other way around.
The Nehalems architechture seems more "serverlike" but will make a bang on the desktop side too.
kingmouf - Thursday, September 25, 2008 - link
I think this is because they have (or should I say had) a different CPU that they wanted to cover that space, the Itanium. But now they are fully concentrated to x86, so...