AMD's Quad-Core Barcelona: Defending New Territory
by Johan De Gelas on September 10, 2007 12:15 AM EST- Posted in
- IT Computing
"Native Quad-Core"
AMD has told the whole world and their pets that Barcelona is the first true quad-core as opposed to Intel's quad-cores which are twin dual cores. This should result in much better scaling, partly a result of the fact that cores should be able to exchange cache information much quicker.
To quantify the delay that a "snooping" CPU encounters when it tries to get up-to-date data from another CPU's cache, take a look at the numbers below. We have used Cache2cache before; you can find more info here. Cache2Cache measures the propagation time from a store by one processor to a load by the other processor. The results that we publish are approximately twice the propagation time.
AMD's native quad-core needs about 76ns to exchange (L1) cache information. That's not bad, but it's not fantastic either as the shared L2 cache approach of the Xeons allows the dual cores to exchange information via the L2 in about 26-30ns. Once you need to get information from core 0 to core 3, the dual die CPU of Intel still doesn't need much more time (77ns) than the quad-core Opteron (76ns). The complex L1-L2-L3 hierarchy might negate the advantages of being a "native" quad-core somewhat, but we have to study this a bit further as it is quite a complex matter.
Memory Subsystem
AMD has improved the memory subsystem of the newest Opteron significantly: the L1 cache is about the only thing that has not been changed: it's still the same 2-way set associative 64KB L1 cache as in K8, and it can be accessed in three cycles. Like every modern CPU, the new Opteron 2350 is capable of transferring about 16 bytes each cycle.
L2 bandwidth has been a weakness in the AMD architectures for ages. Back in the "K7 Thunderbird" days, AMD simply "bolted" the L2 cache onto the core. The result was a relatively narrow 64-bit path from the L2 cache to the L1 cache which could at best deliver about 2.4 to 3 bytes per cycle. The K8 architecture improved this number by 50% and more, but that still wasn't even close to what Intel's L2 caches could deliver per cycle. In the Barcelona architecture, The data paths into the L1 cache have been doubled once again to 256-bits. And it shows:
Barcelona, aka Opteron 23xx, is capable of delivering no less than 50%-60% more bandwidth to its L1 cache than K8. We also measure a latency of 15 cycles, which puts the AMD L2 cache in the same league as the Intel Core caches.
The memory controllers of the third generation of Opterons have also been vastly improved: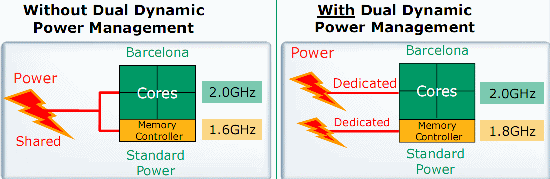
Okay, let's see if we can make all those promises of better memory performance materialize. We first tested with Lavalys Everest 4.0.11.
The deeper buffers and more flexible 2x64-bit accesses have increased the read bandwidth, but the write buffer might have negated the effect of those a bit. That is not a problem, as very few applications will be solely writing for a long period of time. Notice that per cycle, the improved copy bandwidth is 54% and is the biggest gain. This is most likely the result of the copy action resulting in an interleaving of writes and reads, allowing the split memory access design to come into play.
With much higher L2 cache and memory bandwidth combined with low latency access, the memory subsystem of the 3rd generation of Opterons is probably the best you can find on the market. Now let's try to find out if this superior memory subsystem offers some real world benefits.
AMD has told the whole world and their pets that Barcelona is the first true quad-core as opposed to Intel's quad-cores which are twin dual cores. This should result in much better scaling, partly a result of the fact that cores should be able to exchange cache information much quicker.
To quantify the delay that a "snooping" CPU encounters when it tries to get up-to-date data from another CPU's cache, take a look at the numbers below. We have used Cache2cache before; you can find more info here. Cache2Cache measures the propagation time from a store by one processor to a load by the other processor. The results that we publish are approximately twice the propagation time.
| Cache coherency ping-pong (ns) | |||
| Same die, same package | Different die, same package | Different die, different socket | |
| Opteron 2350 | 152 | N/A | 199 |
| Xeon E5345 | 59 | 154 | 225 |
| Xeon DP 5160 | 53 | - | 237 |
| Xeon DP 5060 | 201 | N/A | 265 |
| Xeon 7130 | 111 | N/A | 348 |
| Opteron 880 | 134 | N/A | 169-188 |
AMD's native quad-core needs about 76ns to exchange (L1) cache information. That's not bad, but it's not fantastic either as the shared L2 cache approach of the Xeons allows the dual cores to exchange information via the L2 in about 26-30ns. Once you need to get information from core 0 to core 3, the dual die CPU of Intel still doesn't need much more time (77ns) than the quad-core Opteron (76ns). The complex L1-L2-L3 hierarchy might negate the advantages of being a "native" quad-core somewhat, but we have to study this a bit further as it is quite a complex matter.
Memory Subsystem
AMD has improved the memory subsystem of the newest Opteron significantly: the L1 cache is about the only thing that has not been changed: it's still the same 2-way set associative 64KB L1 cache as in K8, and it can be accessed in three cycles. Like every modern CPU, the new Opteron 2350 is capable of transferring about 16 bytes each cycle.
| Lavalys Everest L1 Bandwidth | |||||
| Read (MB/s) | Write (MB/s) | Copy (MB/s) | Bytes/cycle (Read) | Latency (ns) | |
| Opteron 2350 2 GHz | 32117 | 16082 | 23935 | 16.06 | 1.5 |
| Xeon 5160 3.0 | 47860 | 47746 | 95475 | 15.95 | 1 |
| Xeon E5345 2.33 | 37226 | 37134 | 74268 | 15.96 | 1.3 |
| Opteron 2224 SE | 51127 | 25601 | 44080 | 15.98 | 0.9 |
| Opteron 8218HE 2.6 GHz | 41541 | 20801 | 35815 | 15.98 | 1.1 |
L2 bandwidth has been a weakness in the AMD architectures for ages. Back in the "K7 Thunderbird" days, AMD simply "bolted" the L2 cache onto the core. The result was a relatively narrow 64-bit path from the L2 cache to the L1 cache which could at best deliver about 2.4 to 3 bytes per cycle. The K8 architecture improved this number by 50% and more, but that still wasn't even close to what Intel's L2 caches could deliver per cycle. In the Barcelona architecture, The data paths into the L1 cache have been doubled once again to 256-bits. And it shows:
| Lavalys Everest L2 Bandwidth | |||||||
| Read (MB/s) | Write (MB/s) | Copy (MB/s) | Bytes/cycle (Read) | Bytes/cycle (write) | Bytes/cycle (Copy) | Latency (ns) | |
| Opteron 2350 2 GHz | 14925 | 12170 | 13832 | 7.46 | 6.09 | 6.92 | 1.7 |
| Dual Xeon 5160 3.0 | 22019 | 17751 | 23628 | 7.34 | 5.92 | 7.88 | 5.7 |
| Xeon E5345 2.33 | 17610 | 14878 | 18291 | 7.55 | 6.38 | 7.84 | 6.4 |
| Opteron 2224 SE | 14636 | 12636 | 14630 | 4.57 | 3.95 | 4.57 | 3.8 |
| Opteron 8218HE 2.6 GHz | 11891 | 10266 | 11891 | 4.57 | 3.95 | 4.57 | 4.6 |
| Lavalys Everest L2 Comparisons | |||
| Bytes/cycle (Read) | Bytes/cycle (write) | Bytes/cycle (Copy) | |
| Barcelona versus Santa Rosa | 63% | 54% | 51% |
| Barcelona versus Core | -1% | -5% | -12% |
| Santa Rosa versus Core | -39% | -38% | -42% |
Barcelona, aka Opteron 23xx, is capable of delivering no less than 50%-60% more bandwidth to its L1 cache than K8. We also measure a latency of 15 cycles, which puts the AMD L2 cache in the same league as the Intel Core caches.
The memory controllers of the third generation of Opterons have also been vastly improved:
- Deeper buffers. The low latency integrated memory controller was already one of the strongest points of the Opteron, but the amount of bandwidth it could extract out of DDR2 was mediocre. Only at higher frequencies is the Opteron able to gain a bit of extra performance from fast DDR2-667 DIMMs (compared to DDR-400). This has been remedied in 3rd generation Opteron thanks to deeper request and response buffers.
- Write buffer. When Socket 939 and dual channel memory support was introduced, we found that the number of cycles that bus turnaround takes had a substantial impact on the performance of the Athlon 64. Indeed with a half duplex bus to the memory it takes some time to switch between writing and reading. When you fill up all the DIMM slots in a socket 939 system, the bus turnaround has to be set to two cycles instead of one. This results in up to a 9% performance hit, depending on how memory intensive your application is. So the way to get the best performance is to use one DIMM per channel and keep the bus turnaround at one cycle. However, even better than trying to keep bus turnaround as low as possible is to avoid bus turnarounds. A 16 entry write buffer in the memory controller allows Barcelona to group writes together and then burst the writes sequentially.
- More flexible. Each controller supports independent 64-bit accesses. (Dual core Opteron: a single 128-bit access across both controllers)
- DRAM prefetchers. The DRAM prefetcher works to request data from memory before it's needed when it sees that the memory is being accessed in regular patterns. It can go forward or backward in the memory.
- Better "open page" management. By keeping the right rows ready on the DRAM, the memory controller only has to pick out the right columns (CAS) to get the necessary data instead of searching for the right row, copying the row, and then picking out the right column. This saves a lot of latency (e.g. RAS to CAS), and can also save some power.
- Split power planes. Feeding the memory controller and the core from different power rails is not a direct improvement to the memory subsystem, but it does allow the memory controller to be clocked higher than the CPU core.
Okay, let's see if we can make all those promises of better memory performance materialize. We first tested with Lavalys Everest 4.0.11.
| Lavalys Everest Memory BW | |||||||
| Read (MB/s) | Write (MB/s) | Copy (MB/s) | Bytes/cycle (Read) | Bytes/cycle (write) | Bytes/cycle (Copy) | Latency (ns) | |
| Opteron 2350 2 GHz | 5895 | 4463 | 6614 | 2.95 | 2.23 | 3.31 | 76 |
| Dual Xeon 5160 3.0 | 3656 | 2771 | 3800 | 1.22 | 0.92 | 1.27 | 112.2 |
| Xeon E5345 2.33 | 3578 | 2793 | 3665 | 1.53 | 1.2 | 1.57 | 114.9 |
| Opteron 2224 SE | 7466 | 6980 | 6863 | 2.33 | 2.18 | 2.14 | 58.9 |
| Opteron 8218HE 2.6 GHz | 6944 | 6186 | 5895 | 2.67 | 2.38 | 2.27 | 64 |
| Lavalys Everest Memory BW Comparison | ||||
| Bytes/cycle (Read) | Bytes/cycle (write) | Bytes/cycle (Copy) | Latency (ns) | |
| Barcelona versus Santa Rosa | 26% | 2% | 54% | 29% |
| Barcelona versus Core | 92% | 86% | 111% | -34% |
| Santa Rosa versus Core | 74% | 99% | 44% | -44% |
The deeper buffers and more flexible 2x64-bit accesses have increased the read bandwidth, but the write buffer might have negated the effect of those a bit. That is not a problem, as very few applications will be solely writing for a long period of time. Notice that per cycle, the improved copy bandwidth is 54% and is the biggest gain. This is most likely the result of the copy action resulting in an interleaving of writes and reads, allowing the split memory access design to come into play.
With much higher L2 cache and memory bandwidth combined with low latency access, the memory subsystem of the 3rd generation of Opterons is probably the best you can find on the market. Now let's try to find out if this superior memory subsystem offers some real world benefits.








46 Comments
View All Comments
tshen83 - Monday, October 1, 2007 - link
according to mysql site, starting with 5.0.37, the mutex contention bug and the Innodb bug has been improved by a lot, which helps 8 core systems.I was wondering that since 5.0.45 is available on mysql's website, why isn't the latest mysql being benchmarked? 5.0.26 still has that bug, and you can see it in the benchmark where a 8 core system is slower than a 4 core which is slower than a 2 core.
Now that we are benchmarking 8-16 core systems, the newest versions of software should be used to reflect the improved multithreading.
swindelljd - Wednesday, September 12, 2007 - link
I currently have a 4 way 2.4ghz opteron as a production db server that I am considering upgrading. I'm trying to use the Anandtech benchmarks to help project how much performance gain we'll see in a new machine.We're running Oracle but are considering moving to MySQL. So I am trying to compare the stat's in 2 Anandtech reviews to see how the new Barcelona cores compare to the Intel Woodcrest and Clovertown.
In looking at this article from June 2006( http://www.anandtech.com/IT/showdoc.aspx?i=2772&am...">http://www.anandtech.com/IT/showdoc.aspx?i=2772&am... ) , 2x3ghz Woodcrests (4 cores, right?) run the MySQL test at about 950 QPS (queries per second) for 25,50 and 100 concurrent sessions.
However this recent article in September 2007 ( http://www.anandtech.com/IT/showdoc.aspx?i=3091&am...">http://www.anandtech.com/IT/showdoc.aspx?i=3091&am... ) appears to show the same 2x3ghz Woodcrests running 700,750 and 850 QPS for 25,50 and 100 connections respectively. That represents a 20% or so DECREASE in performance of the same chip in the last 12 months.
What am I missing?
Ultimately I want to compare the Opteron 2350 vs Xeon 5345 and then the Opteron 8350 vs Xeon E7330 but I'm starting with what exists for benchmarks first so I can make sure I understand what I am reading.
Can someone please help set me straight.
thanks,
John
JohanAnandtech - Monday, September 17, 2007 - link
The article in june 2006 uses 5.0.21, and there might also be a small change in tuning. The article in September 2007 uses the standaard 5.0.26 mysql version that you get with SLES 10 SP1.The best numbers are here:
http://www.anandtech.com/cpuchipsets/intel/showdoc...">http://www.anandtech.com/cpuchipsets/intel/showdoc...
The newest version 5.0.45 will give you performance like the above article: MySQL has incorporated the Patches we talked about (that Peter Z. wrote) in this new version.
Jjoshua2 - Tuesday, September 11, 2007 - link
I like this benchmark alot as I am a fan of computer chess. Higher was spelled wrong on the graph on that page in Hiher is better.Schugy - Tuesday, September 11, 2007 - link
Maybe it's too early for gcc optimizations but how about testing programs like oggenc, ffmpeg, blender, kernel compilation, apache with openssl, doom III and so on?erikejw - Monday, September 10, 2007 - link
I read another review and they got these scores on the slightly lowerspeed 1.9 GHz Barcelona.Barcelona 2347 (1.9Ghz)
37.5 Gflop/s
Intel Xeon 5150(2.6Ghz)
35.3 Gflop/s
It seems your Barcelona scores are way off for some reason.
The Xeons score is more or less identical.
This seems really weird. Normally the higher score is the correct one due to some bad optimizations. The rest of the article is great though.
kalyanakrishna - Monday, September 10, 2007 - link
This article seems to be very biased.1) they choose faster Intel processors, 2 GHz Opteron. There are 2 GHz processors available across all the processors used in this analysis.
2) No mention of what compiler was used. Intel compilers earlier had a trick, which was not documented - any code optimized for Intel processors if used on non-intel processors (uhm! AMD), would disable all optimizations. Who knows what else they are doing now. And this gentleman used Intel optimized code on AMD to test performance. Who in the right mind measuring performance would do that?
3) Intel MKL was used for BLAS. Shouldnt they use ACML for AMD code? Again, who would do that when looking for performance?
4) Memory Subsystem - knowing that the frequencies are different, why were all the results not normalized?
5) They managed to comment that Tulsa and Opteron 2000 series are half the performance of core or Barcelona and hence should not be considered in the first page. But in Linpack page, it is mentioned that Intel chips ate AMD ones for breakfast. Of course, they did - peak of Xeon 5100 series is twice that of Opteron 2000 series. You dont need LINPACK to tell you that. Gives a very biased impression.
6) LinPACK results graph could not be any more wrong. The peak performance of each CPU considered is different ... obviously their sustained performance is going to be different. The author should have at least made the effort to normalize the graph to show the real comparison.
7) Since when is Linpack "Intel friendly"
The author says they didnt have time to optimize code for AMD Opteron ... why would you do a performance study in the first place if you didnt have the methodology right.
I didnt even read beyind LinPACK .. I would be careful reading articles from this author next time and maybe the whole site ... Its sad to see such an immature article. Whats worse is majority of people would just see the "fact" Intel is still faster than AMD.
Over all, a very immature article with false information cleverly hidden behind numbers. or could it be that this article was intended to be biased .... who knows.
JohanAnandtech - Monday, September 10, 2007 - link
What about the bytes/Cycle in each table?
Why is that the "real comparison"? If Intel has a clockspeed advantage, nobody is going to downclock their CPUs to be fair to AMD.
First you claim we are biased. As we disclose that the binary that we run was compiled with Intel compilers targetting Core architecture, it is clear that the binary is somewhat Intel friendly.
It not wrong. It is incomplete and we admit that more than once. But considering AMD gaves us a few days before the NDA was over, it was impossible to cover all angles.
erikejw - Tuesday, September 11, 2007 - link
That is true in the desktop scene but I am sure you know that servers is about performance/price and performance/w. Prices will declinge and we don't know what the price is tomorrow. It is ok to compare against a similarly priced cpu but a comparison against a
same frequency cpu is very interesting too.
Your LINPACK score just seems obscure. Somewhat Intel friendly compiler? LOL. If the compiler is so great why is the gcc score I read on another review 30% higher with the Barcelona(with a 1.9 GHz CPU)? That is just ridiculous. I thought this review was about architechture and what it can perform and not about which compiler we use and if it is true that optimizations is turned off in then Intel compiler if it is an AMD cpu then the score is worthless and the comparison is severly biased.
JohanAnandtech - Tuesday, September 11, 2007 - link
Which review? Did they fully disclose the compiler settings?
If the Intel compiler did fool us and turned off optimisations, we will update the numbers.