Supermicro's Twin: Two nodes and 16 cores in 1U
by Johan De Gelas on May 28, 2007 12:01 AM EST- Posted in
- IT Computing
Network Load Balancing
It is pretty clear that we can not test the Supermicro 1U Twin in a conventional manner. Testing one node alone doesn't make sense: who care if it is 1-2% faster or slower than a typical Intel 5000p chipset based server? So we decided to use Windows 2003 Network Load Balancing or software load balancing. NLB is used mostly for splitting the load of heavy web-based traffic over several servers to improve response times, throughput and more importantly, availability. Each node sends a heartbeat signal. If a host fails and stops emitting heartbeats, the other nodes will remove it from their NLB cluster information, and although a few seconds of network traffic will be lost, the website remains available. What is even better is the fact that NLB, due to the relatively simple distributed filtering algorithm on each node, puts very little load on the CPUs of the node. The heartbeat messages also consume very little bandwidth. Testing with a fast Ethernet switch instead of our usual Gigabit Ethernet switch didn't result in any significant performance loss, whether we talk about response time (ms) or throughput (URLs served per second).
With four and up to eight CPUs per node, it takes a while before the NLB cluster becomes fully loaded, as you can see at the picture below.

Web server measurements are a little harder to interpret than other tests, as you always have two measurements: response time and throughput. Theoretically, you could set a "still acceptable" maximum response time and measure how many requests the system can respond to without breaking this limit. However, in reality it is almost impossible to test this way, as we simulate a number of simultaneous users which send requests and then measure both response time and throughput. Each simultaneous user takes about one second to send a new request. Notice that the number of simultaneous user is not equal to the total number of users. One hundred simultaneous users may well mean that there are 20 users constantly clicking to get new information while 240 others are clicking and typing every 3 seconds.
Another problem is of course that in reality you never want your web server to be at 100% CPU load. For our academic research, we track tens of different parameters, including CPU load. For a report such as this one, this would mean however that you have to wade through massive tables to get an idea how the different systems compare. Therefore, we decide to pick out a request rate at which all systems where maxed out, to give an idea of the maximum throughput and the associated latency. In the graphics below, 200 simultaneous users torture the MCS web application requesting one URL every second.
The single node tests are represented by the lightly colored graphs, the darker graphs represent our measurement in NLB mode (2 nodes). We were only able to get four Xeon E5320 (quad core 1.86 GHz Intel Core architecture) processors for this article, unfortunately; it would have been nice to test with various other CPUs in 4-way configurations, but sometimes you have to take what you can get.
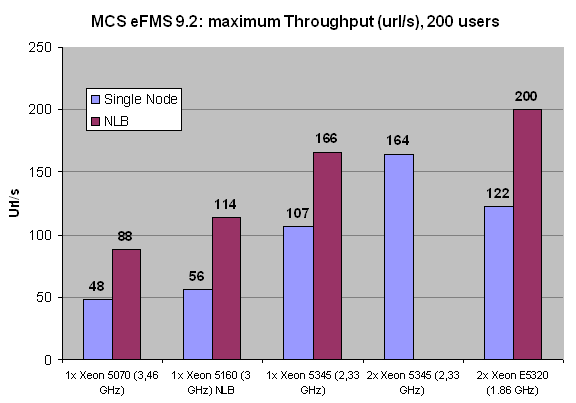
Notice that two CPUs connected by NLB and thus Gigabit Ethernet are not slower than two CPUs connected by the FSB. In other words, two nodes with one CPU per node are not slower than two CPUs in a single node. The most likely explanation is that the overhead of communicating over a TCP/IP Ethernet connection is offset by the higher amount of bandwidth that each CPU in the node has available. From the numbers above we may conclude that NLB scales very well: adding a second node increases the throughput by 60 to 100%. Scaling decreases as we increase the CPU power and the number of cores which is no surprise, as the latency of the Gigabit connection between the nodes starts to become more important. To obtain better scaling, we would probably have to use an InfiniBand connection but for this type of application that seems a bit like overkill.
Also note that 200 users means 200 simultaneous users which may translate - depending on the usage model of the client - to a few thousands of real active users in a day. The only configuration that can sustain this is the NLB configuration: in reality it could serve about 225 simultaneous users at one URL/s, but as we only asked for 200, it served up 200.
To understand this better, let us see what the corresponding response time is. Remember that this is not the typical response time of the application, but the response you get from an overloaded server. Only the 16 Xeon E5320 cores were capable of delivering more than 200 URL/s (about 225), while the other configurations had to work with a backlog.
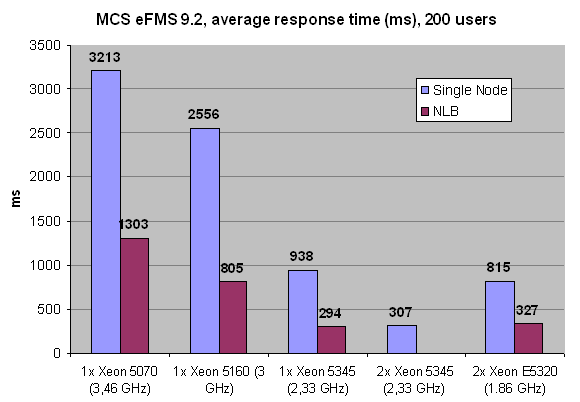
It is a bit extreme, but it gives a very good idea of what happens if you overload a server: response times increase almost exponentially. When we tested with 100 users, our dual Xeon E5320 (1.86 GHz, four cores in one node) provided a response time of about 120 ms on average per URL - measured across about 40 different URLs - and so did the same configuration in NLB (two nodes). A Xeon 5160 in each node in NLB responded in 145 ms, as the demanded throughput was much closer to its maximum of 114 ms. Now take a look at the measured response times at 200 URL/s.
The Xeon Dempsey 5070 (dual core 3.46 GHz 2MB NetBurst architecture) is only capable of sustaining half the user requests we demand from it, and the result is a 10X higher response time than our two node 16 core NLB server, or almost 30X higher than the minimum response time. Our quad Xeon 1.86 in NLB was capable of a response time of 327 ms, almost 3X higher than the lowest measured response time at 100 URL/s. So we conclude that pushing a web server to 90% of its maximum will result in a ~3X higher response time. This clearly shows that you should size your web server to work at about 60%, and no peak should go beyond 90%. Overload your web server with twice the traffic it can handle, and you'll be "rewarded" with response times that get 30X higher than the minimum necessary response time.
It is pretty clear that we can not test the Supermicro 1U Twin in a conventional manner. Testing one node alone doesn't make sense: who care if it is 1-2% faster or slower than a typical Intel 5000p chipset based server? So we decided to use Windows 2003 Network Load Balancing or software load balancing. NLB is used mostly for splitting the load of heavy web-based traffic over several servers to improve response times, throughput and more importantly, availability. Each node sends a heartbeat signal. If a host fails and stops emitting heartbeats, the other nodes will remove it from their NLB cluster information, and although a few seconds of network traffic will be lost, the website remains available. What is even better is the fact that NLB, due to the relatively simple distributed filtering algorithm on each node, puts very little load on the CPUs of the node. The heartbeat messages also consume very little bandwidth. Testing with a fast Ethernet switch instead of our usual Gigabit Ethernet switch didn't result in any significant performance loss, whether we talk about response time (ms) or throughput (URLs served per second).
With four and up to eight CPUs per node, it takes a while before the NLB cluster becomes fully loaded, as you can see at the picture below.
Web server measurements are a little harder to interpret than other tests, as you always have two measurements: response time and throughput. Theoretically, you could set a "still acceptable" maximum response time and measure how many requests the system can respond to without breaking this limit. However, in reality it is almost impossible to test this way, as we simulate a number of simultaneous users which send requests and then measure both response time and throughput. Each simultaneous user takes about one second to send a new request. Notice that the number of simultaneous user is not equal to the total number of users. One hundred simultaneous users may well mean that there are 20 users constantly clicking to get new information while 240 others are clicking and typing every 3 seconds.
Another problem is of course that in reality you never want your web server to be at 100% CPU load. For our academic research, we track tens of different parameters, including CPU load. For a report such as this one, this would mean however that you have to wade through massive tables to get an idea how the different systems compare. Therefore, we decide to pick out a request rate at which all systems where maxed out, to give an idea of the maximum throughput and the associated latency. In the graphics below, 200 simultaneous users torture the MCS web application requesting one URL every second.
The single node tests are represented by the lightly colored graphs, the darker graphs represent our measurement in NLB mode (2 nodes). We were only able to get four Xeon E5320 (quad core 1.86 GHz Intel Core architecture) processors for this article, unfortunately; it would have been nice to test with various other CPUs in 4-way configurations, but sometimes you have to take what you can get.
Notice that two CPUs connected by NLB and thus Gigabit Ethernet are not slower than two CPUs connected by the FSB. In other words, two nodes with one CPU per node are not slower than two CPUs in a single node. The most likely explanation is that the overhead of communicating over a TCP/IP Ethernet connection is offset by the higher amount of bandwidth that each CPU in the node has available. From the numbers above we may conclude that NLB scales very well: adding a second node increases the throughput by 60 to 100%. Scaling decreases as we increase the CPU power and the number of cores which is no surprise, as the latency of the Gigabit connection between the nodes starts to become more important. To obtain better scaling, we would probably have to use an InfiniBand connection but for this type of application that seems a bit like overkill.
Also note that 200 users means 200 simultaneous users which may translate - depending on the usage model of the client - to a few thousands of real active users in a day. The only configuration that can sustain this is the NLB configuration: in reality it could serve about 225 simultaneous users at one URL/s, but as we only asked for 200, it served up 200.
To understand this better, let us see what the corresponding response time is. Remember that this is not the typical response time of the application, but the response you get from an overloaded server. Only the 16 Xeon E5320 cores were capable of delivering more than 200 URL/s (about 225), while the other configurations had to work with a backlog.
It is a bit extreme, but it gives a very good idea of what happens if you overload a server: response times increase almost exponentially. When we tested with 100 users, our dual Xeon E5320 (1.86 GHz, four cores in one node) provided a response time of about 120 ms on average per URL - measured across about 40 different URLs - and so did the same configuration in NLB (two nodes). A Xeon 5160 in each node in NLB responded in 145 ms, as the demanded throughput was much closer to its maximum of 114 ms. Now take a look at the measured response times at 200 URL/s.
The Xeon Dempsey 5070 (dual core 3.46 GHz 2MB NetBurst architecture) is only capable of sustaining half the user requests we demand from it, and the result is a 10X higher response time than our two node 16 core NLB server, or almost 30X higher than the minimum response time. Our quad Xeon 1.86 in NLB was capable of a response time of 327 ms, almost 3X higher than the lowest measured response time at 100 URL/s. So we conclude that pushing a web server to 90% of its maximum will result in a ~3X higher response time. This clearly shows that you should size your web server to work at about 60%, and no peak should go beyond 90%. Overload your web server with twice the traffic it can handle, and you'll be "rewarded" with response times that get 30X higher than the minimum necessary response time.








28 Comments
View All Comments
JohanAnandtech - Monday, May 28, 2007 - link
Hey, you certainly gave the wrong impression of yourself with that first post, not our fault.Anyway NLB, infiniband and rendering farms are not anymore exotic than 802.3 ad link aggregation. So I am definitely glad that you and a lot of people want to look beyond the typical gaming technology.
That is somewhat in contradiction with being an "enthousiast" as "enthousiast" means that technology is a little more than just a tool.
Yep, but why hide it ?
Well it is hardly about the product alone, as we look into NLB and network rendering, which is exactly using the technology for a mean.
While do get the point of your second post, your first post doesn't make any sense: 1) this kind of server should never be turned into a iSCSI device: there are servers that can have more memory and have - more importantly - a much better storage subsystem. 2) you give the impression that an enthousiast site should not talk about datacenter related stuff.
Hey man, my purpose here is certainly not making fun of you. You seem like a person that can give a lot better feedback than you did in your first post. By all means do that :-)
A lot of data administrators are very capable certified people in the world of networking and Server OS. But very few know their hardware or can decently size it. I read a book from O'reilly about datacenters a while ago. The stuff about the electrical and networking part of datacenters was top notch. The part about storage, load balancing and sizing were very average. And I believe a lot of people are in that case.
yyrkoon - Monday, May 28, 2007 - link
Well I suppose you are right to an extent here, maybe I like hardware so much that I tend to spend more time 'researching' different hardware?
The last thing I really want to convey is that I know EVERYTHING, which if I actually thought this, I would most likely be dillusional(this goes for everyone, not just myself, and no, I am not pointing any fingers, I am just saying that perhaps I come off as a know-it-all, but I really dont know it all).
Anyhow, my original post ws more of a joke, with the serious part, being if somehow this equipment landed its self in my home, I would actually do with it as I said. I do not work in a data center, but I do contract work for small business a lot, mostly for media broadcasters, and the occational home PC when business as such presents its self, so obviously there are things the datacenter monkies know that I do not.
All that being said, I can not hide the fact that home PC hardware is where my enthusiasm stems from, concerning technology. I see great things for technology like Infiniband, SAS, but these technologies are all but useless in the home because it is being driven by enterprise consumers, that usually dont care about 'reasonably' priced hardware, that performs well in the home envoirnment.
As I stated before, I have been following the PCIe v2.0 technology for a bit now, and I was under the impression that PCIe-PCIe direct communications were not going to be implemented outside of PCIe v2.0, and would have a good chance of being reasonably priced enough, to be used in the home (on a smaller scale, say 4x channels, instead of the potential of 32x channels). Now, I am dissapointed in seeing that while it may improve server performance, this is going to be used as an excuse to bleed home users dry of cash. Just like SAS, hardware wise, it is comparable in price to say firewire once you pass a certain HDD count threshhold, but finding standalone expanders (without a 2.5" formfactor removable drive bay, or LSI built 1U or greater rack), are non existant(or at least, I personally have not been able to find any). This means people like me, who are wanting to build SoHo like storage for personal, or small business get left out in the cold, AGAIN. Would'nt you like to have a small server at home capable of delivering decent disk throuput/access speeds(ie external to your desktop PC) for a reasonable price ? I know I would.
All in all, I find the hardware interresting, yet find myself dissapointed from the home use aspect. SO this is why I can hardly be excited by such news.
TA152H - Monday, May 28, 2007 - link
Johan,I think labels are bad in general, and the enthusiast site is more often an excuse than a valid explanation for some of the choices. It gets annoying, because there is no reason why you can't do both. If someone doesn't want to read your articles on a topic, they can skip it, right?
However, I have a few issues, naturally :P. Not that you weren't complimentary towards Supermicro, but I'm not sure you carried it quite far enough. Comparing Supermicro to Dell is kind of insulting to Supermicro. Also, you seemed to leave out that Supermicro sells motherboards, cases, power supplies, etc... as standalone pieces, and they are considered by most professionals to be the best motherboards made, as well as being supported extremely well. You can't kill these motherboards, I still run a P6DLE (440LX!) that I want to upgrade but it just won't die. They never do, and the components and fit and finish are absolutely top notch. Now before someone who likes Intel screams at me, they make excellent motherboards too and are extremely high quality as well. But, Intel doesn't make motherboards for AMD, Supermicro does. And if you're building a server, and want AMD, do you really want some junk from Taiwan? Sure, they're cheap, but you buy Asus or Tyan and you're whistling past the graveyard with that rubbish. On top of this, you can even buy Supermicro motherboards that are not server motherboards (my first was a desktop one, P5MMA, and it still works as a print server). There are plenty of white boxes sporting Supermicro motherboards, and some companies build their own in house with Supermicro components. So, their market share is considerable higher than just those sold as complete servers.
Also, you're insistence on a redundant power supply, I think, misses the point completely. You can buy Supermicros with redundant power supplies, and if that's what you wanted, review one of them. This was made for a different purpose, and you absolutely do NOT want it. That would defeat the purpose, so saying how they should get it is kind of silly. Saving 100 watts is absolutely enormous, especially when getting something inexpensive, and from the most reputable company in server motherboards. By the way, have you ever killed a Supermicro power supply? I haven't, and I do try. So, yes, maybe power supplies fail more often for the cheap companies, but I think the failure rate for Supermicro is very low. But realistically, you have to consider if you can tolerate it at all. If you can't, get one of their other products. If you can, then the power savings are incredible. It's nice to have both choices, isn't it?
If you want the best and can pay, Supermicro is the way to go. When they are inexpensive and have excellent power use characteristics, it's almost irresistable if it is the type of product you want. Dell??? Oh my. You'd have to be crazy.
JohanAnandtech - Monday, May 28, 2007 - link
So much feedback, thanks! Makes these horrible long undertakings called "server articles" much more rewarding even if you don't agree.Just leave your first name next time, I like to address you in a proper way.
Anyway, your feedback
Read my article again, and you'll understand my POV better. I work with a lot of SMBs, like MCS, and they like to run their webserver in NLB for fail over reasons. For that, the supermicro twin could be wonderful: pay half as much colocation costs than normal. And notice that I did remark that the percentage of downtime due to a PSU failure is relatively small and it is probably an acceptable risk for many SMBs.
I just hope I can challenge Supermicro enough to get two PSUs in there. The Twin is an excellent idea, and it would be nice to have it as high availability solution too. So no, just reviewing another supermicro server won't cut it: you double the rackspace needed.
TA152H - Monday, May 28, 2007 - link
Johan,I just thought of a few things after writing that, and have moved closer to your point of view. Oh, my name is Rich, sorry, I forgot to mention that in the first one.
Maybe it isn't possible to create a server with the same feature set as this one, in 1U with a redundant power supply. My first reaction was when you are asking for this, you were willing to put up with something bigger, which is an option. Another option is to impose limitations on the server, and still fit it in 1U. By removing some features, and imposing limitations, for example what processors can be used, you might be able to do it. Not only could you reduce the motherboard size, but you could also reduce the power supply if you can safely say that fewer watts can be used. And it's significant, because you multiply it by two, or four in the case of processors. If you lower the acceptable power use for the processor by say 30 watts, you reduce the power supply by 120 watts, so it's significant. If you make it ULV, you could realize some very serious savings, as well as reduce cooling issues. Between this and removing some features, they might be able to significantly reduce power use, and at the same time make the motherboard a little smaller.
On the other hand, I think SAS would complicate things, and might be why they left it out. I don't think you can get everything in this type of box right now, but maybe another choice would be to create more choices by leaving certain things out, and allowing other things (redundant power supply) to be put in. Of course, I don't know for sure if it's possible, but it might be.
MrSpadge - Monday, May 28, 2007 - link
Rich,that's roughly what I thought as well when I read your first post. "It's too cramped, they can't get 2 x 900 W with high quality in there" Then I was about to post that it may be possible to get away with a two smaller PSUs and started to name the power consuming devices: 4 x 120 W CPUs, 32 x 5-7 W FB-DIMMs, 4 x 10 W HDD plus something for the chipsets and some loss in the CPU core voltage converters. And I realized that even 700W is probably not enough for this hardware, so I scrapped my post.
To reduce power consumption they'd really have to constrain the use of CPUs and maybe limit the machines to 8 FB-DIMMs per machine, which is still a lot of memory. The 80W 2.33 GHz quad Xeon may be the best candidate for this. One could also think about using either 2.5" 7200 rpm notebook drives (uhh..) or Seagate Savvios. Less cost effective than 3.5" SATA but you save some more space and power.
MrS
TA152H - Monday, May 28, 2007 - link
Johan,I think I know where we disagree. I do understand your point, but I don't think what you're asking for is possible. The problem is, how do you get two power supplies of that rating into that size case? Consider, if you will, you still need a massive power supply to be able to handle both, the case is already crammed pretty well. To get two dual motherboards in there in the first place is and to create such an attractive product is already a great accomplishment. I just don't think you can stuff two 900 watt power supplies in there. Addressing a challenge and beating the laws physics are two different things, I think, right now, it is a bridge too far (a reference to a historic battle in your country, I hope you appreciate it :P). Even if they do get a twin in there, which again, I think is nearly impossible, you'd lose some power efficiency, and add some cost. So, it wouldn't be painless. But, you know, it would make for a good choice to have, so I'm not against it. Both would be attractive. But, I just don't see how they could do it. I don't even know any company has a 2 x Dual available in 1U yet, so it's not trivial. Of course, I can't say for sure it's impossible, it's not like I really know enough to.
yyrkoon - Monday, May 28, 2007 - link
Take out all but 2-4 cores, slap in another 16 GB ram for a total of 32GB, use Windows2003 iSCSI/export 31GB of ram disk, and you have a decently fast, very low latency 'disk'. All for 2000x the cost of a similar sized HDD ;) Weeeeeeeeee!Sorry guys, I thought this was an 'enthusiast' site, and was briefly confused :P If I had one of the mentioned systems, this is prpobably fairly accurate as to how I would use it . . .